
 首页
首页 项目投稿
项目投稿 寄售资源卖!
寄售资源卖! 问答悬赏爆!
问答悬赏爆! 提交工单
提交工单 在线聊天室24h
在线聊天室24h 优站导航汇集
优站导航汇集

今天介绍一款开源的OCR工具
MonkeyOCR 是由 Yuliang‑Liu 团队开发的一款轻量级文档结构化解析模型,采用基于结构-识别-关系(SRR)三元组 Paradigm方法。
该项目在GitHub上收获5.1k⭐,专注于将PDF或图像文档自动转换为结构化Markdown内容,支持复杂排版如表格、公式、公式及关系推理,擅长中文和英文文档处理。
适合科研、文档自动化处理和批量数据提取需求。
应用特性
-
结构‑识别‑关系三元组机制:先检测布局结构(结构),再识别内容(识别),最后推断块间逻辑顺序(关系),摆脱传统大模型效率低下问题。
-
性能强悍:1.2B参数版本在中文文档上比 3B 模型提升 7.4%,速度提升约 36%。
-
高准确率:在多种benchmark上表现优异,如比 MinerU 整体提升 5.1%,公式识别提升达 15%、表格识别提升 8.6%。
-
兼容中文英文:支持复杂布局、金融报表、新闻排版、手稿识别,适配多语言多场景。
-
高效部署:3B 模型支持单张NVIDIA3090GPU 推理,并提供 Docker 部署与在线 demo。
-
文档与Demo完整:提供arXiv论文、GitHub示例、HuggingFace 模型与可视化Demo页面。
应用相关截图
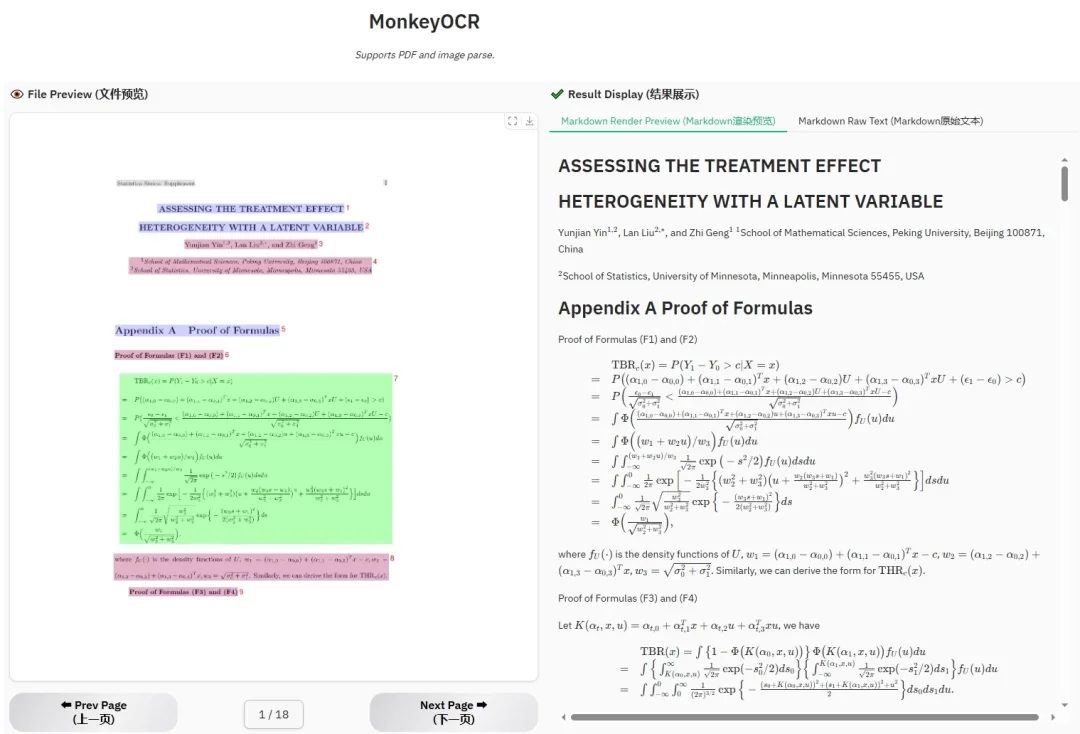
应用特性
- 上传 PDF → 解析输出结构化Markdown
- 支持复杂公式、表格与段落自动识别
- 各文档类型解析实例(报表、报纸、公式文档等)
部署方式 Python + Docker
git clone https://github.com/Yuliang-Liu/MonkeyOCR.git
cd MonkeyOCR
# 使用 Docker 部署
docker build -t monkeyocr .
docker run -p 8080:8080 monkeyocr
# 或 Python 本地安装
pip install -r requirements.txt
python parse.py --input sample.pdf运行服务后,通过网页上传 PDF 或调用脚本即可获得结构化输出。
下载地址
温馨提示:本站提供的一切软件、教程和内容信息都来自网络收集整理,仅限用于学习和研究目的;不得将上述内容用于商业或者非法用途,否则,一切后果请用户自负,版权争议与本站无关。用户必须在下载后的24个小时之内,从您的电脑或手机中彻底删除上述内容。如果您喜欢该程序和内容,请支持正版,购买注册,得到更好的正版服务。我们非常重视版权问题,如有侵权请邮件与我们联系处理。敬请谅解!
联系邮箱:lgg.sinyi@qq.com

